
It’s 3 AM in a data center. A mainframe is crunching millions of transactions, batch jobs are running, reports are being generated. But half those jobs process empty files, reports go unread, and engineers who log in at 9 AM spend their day fixing JCL errors instead of building new solutions.
When the business team asks simple questions like “Can we cut costs?” or “Which applications are critical?”, the answers take weeks—digging through old docs, chasing tribal knowledge, and depending on the one expert who’s been around since the ’90s.
And modernization isn’t as simple as “move it to the cloud.” Mainframes hold decades of business rules and hidden dependencies. A single COBOL job might move money, trigger compliance checks, or update dozens of reports. Rewriting without that knowledge risks breaking the very systems the business runs on.
1. Introduction
I’m Vijay Aditya, an undergraduate at IIT BHU exploring how AI can transform enterprise systems. In my research on mainframe modernization, I began asking a simple question: what if the mainframe could answer for itself?
Imagine asking, “Which batch jobs haven’t run in six months?” and getting an instant answer. Or the system warning you, “This month’s workload will add $50,000 in costs—here’s how to prevent it.” Now push further: what if the mainframe could modernize itself, safely and continuously?
2. Progress after Mid Term:
After mid-term, I built a demo with four agents (Discovery → Analysis → Roadmap → Execution). It could scan COBOL/JCL, find dependencies, estimate cost and complexity, and suggest whether to refactor, rehost, rewrite, or retire code. It used RAG for grounding and a CI loop for testing small code changes.
But the system had clear limits:
- Agents worked in a straight line with no memory or feedback.
- Logic relied only on prompts, so results sometimes drifted.
- Governance was weak—approvals and audits weren’t clear.
- Focus was too narrow on code conversion, not bigger goals like cost or performance.
- No knowledge layer to handle missing docs or past decisions.
- Roadmaps didn’t consider risks.
To fix this, I rebuilt the system into a four-layer architecture. It now has a strong data foundation, an institutional memory, orchestration, and specialist agents—all with role-based access, policy checks, and a feedback loop. Every action is auditable and improves the knowledge base.
3. Primary Objectives
Create Universal Mainframe Intelligence
An AI layer that:
- Understands Everything: Builds a complete knowledge graph from COBOL, JCL, SMF, DB2, and more.
- Speaks Human Language: Translates technical complexity into clear business insights.
- Remembers Forever: Preserves institutional knowledge that usually leaves with retiring experts.
Enable Continuous Cost Optimization
Delivers measurable savings by:
- Real-Time MSU Management: Predicting and preventing costly peaks.
- Intelligent Resource Allocation: Cutting waste while protecting critical operations.
- Strategic Modernization Roadmap: Recommending what to modernize, migrate, or maintain with ROI projections.
Accelerate Business Agility
Turns the mainframe into an enabler by:
- Instant Impact Analysis: Answering “what if” questions in seconds.
- Automated Modernization Execution: Implementing changes from code to deployment.
- Self-Service Analytics: Letting business users query data without technical expertise.
4. Layer-by-Layer Architecture Design:
4.1. Layer 1: Interface & Session (Omnichannel Intelligence Gateway):
A universal front door to mainframe intelligence. It hides the “green‑screen” complexity behind clean, modern touchpoints so anyone—from a CEO in a board meeting to an engineer on call—can ask questions and get precise answers.
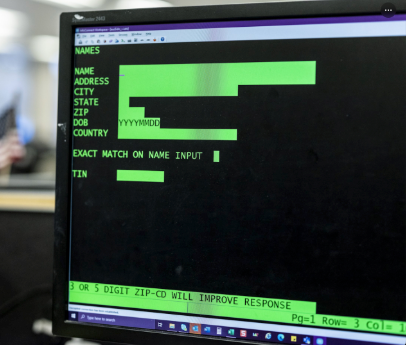
Legacy mainframe terminal screen with data entry fields highlighting the complexity of traditional mainframe systems
Key Components:
- Multi-channel access:
- Web Console with dashboards, queries, and visualizations
- CLI for DevOps automation
- ChatOps (Slack/Teams): ask questions directly in team channels
- REST API for integration with business apps
- Contextual session management: Remembers queries, filters, and timeframes. Example: After asking “Show MIPS by LPAR for Q3,” a follow-up like “Drill into LPAR-3 last month” is understood automatically.
- Security-first design: Role-based access ensures executives see summaries while engineers see details. Built-in SSO and multi-factor authentication safeguard access.
4.2. Layer 2: Knowledge Intelligence (Institutional Memory Engine):
Creates an understanding of the entire mainframe ecosystem that remembers not just what systems do, but why they were built and what depends on them.
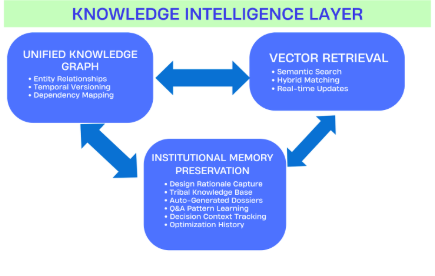
Architecture Overview: The Three-Brain System
4.2.1.Unified Knowledge Graph Architecture:
The z/OS Knowledge Graph is designed to capture and connect every part of the mainframe ecosystem. It models entities like programs, jobs, datasets, tables, copybooks, transactions, LPARs, owners, and business capabilities, while also mapping execution flows, data lineage, costs, and historical changes. Built on Neo4j, it combines scalable graph storage with custom parsers for mainframe artifacts.
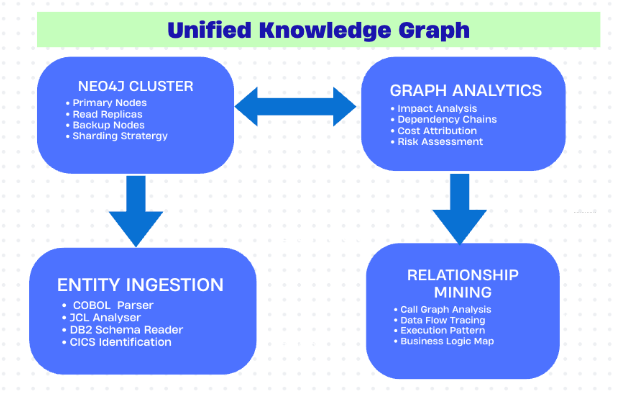
Implementation Architecture
Core Components:
- Neo4j Cluster:
The backbone of the graph. A primary node manages updates, replicas handle user queries, backups ensure recovery, and sharding allows the system to scale by splitting data across business areas or geographies. - Graph Analytics:
Turns connections into insights. It shows how one job impacts others, reveals dependency chains, attributes IT costs to specific apps or business units, and ranks systems by criticality and risk. - Entity Ingestion:
Specialized parsers bring mainframe components into the graph: COBOL programs and copybooks, JCL jobs and schedules, DB2 tables and schemas, and CICS transactions. These become graph nodes enriched with metadata like owners, SLAs, run stats, and last-change dates. - Relationship Mining:
Builds the links that make the graph valuable. It maps which programs call each other, how data flows between jobs and datasets, runtime execution patterns, and how technical processes support business functions (e.g., Billing Program → Customer Billing).
4.2.2. Vector Retrieval System:
This system makes all mainframe knowledge searchable by combining code, configs, docs, and expert insights into a semantic layer that updates in real time.
Key Features:
- Comprehensive coverage: COBOL/PL/I/Assembler, JCL, DB2, CICS, runbooks, and incident histories.
- Hybrid search: Mixes keyword and semantic search for precise results.
- Real-time ingestion: Continuously updates from Git/Endevor, SMF streams, z/OSMF APIs, and CMDBs.
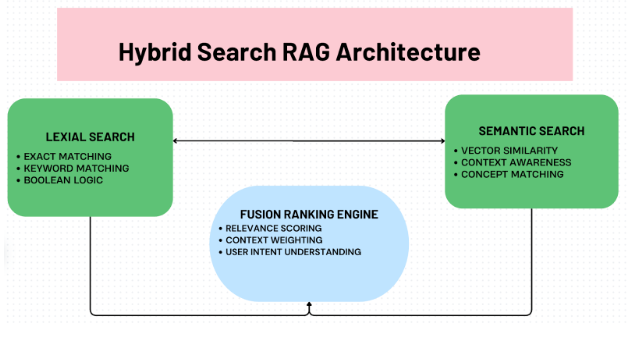
How It Works
Vector embeddings turn code and text into mathematical representations that capture meaning. This allows the system to find conceptually related content, not just keyword matches.
Example: A query like “Find code that validates customer credit limits” can match across programs like CREDITVAL.CBL or LIMCHECK.CBL, even if the exact words differ.
Core Capabilities:
- Semantic Code Search
Lets users find relevant code by describing its purpose in plain language. Matches are based on comments, identifiers, and logic patterns, not just exact strings. - Documentation Mining
Makes both structured docs (designs, runbooks, compliance records) and unstructured notes (emails, wikis, incident reports) searchable.
Example: Query “How do we handle month-end failures?” could return a runbook, an incident report, and related email threads. - Expert Knowledge Base
Captures insights from SMEs through interviews, decision patterns, and lessons learned.
Example: An expert note on BILLING_CALC explained a dataset contention issue and its fix, reducing runtime by 40%. - Real-Time Updates
Tracks changes in code, docs, and configs, then re-indexes automatically to keep results accurate.
Example: When a COBOL validation program is updated in Git, its new logic is re-vectorized and immediately searchable.
4.2.3. Institutional Memory Preservation:
This “wisdom layer” goes beyond documenting what systems do—it captures why decisions were made, how problems were solved, and what lessons were learned. It transforms tribal knowledge from retiring experts into searchable intelligence for safer modernization.
Three Pillars:
- Architecture Decision Records (ADRs): Linked directly to code, systems, and configurations.
- Tribal Knowledge: Q&A patterns, troubleshooting steps, and optimization lessons.
- System Dossiers: Auto-generated profiles for applications, LPARs, and services with real-time operational data.
Outcomes:
- Prevents knowledge loss (captures >90% of expertise).
- Cuts diagnosis time from hours to minutes.
- Enables risk-aware modernization with complete decision history.
ADR Management System
Automates the full ADR lifecycle—from detecting new decisions to drafting, validating, and maintaining them—while keeping human oversight for critical choices.
- Graph Integration: Maps ADRs to code, systems, people, and other ADRs, revealing dependencies and conflicts.
Example: Query “ADRs affecting PAYROLL” returns decisions on database, APIs, and security spanning 15 years. - RAG Integration: Uses semantic search to surface the most relevant ADRs, troubleshooting guides, and lessons.
Example: Query “batch job performance issues” may return an ADR on connection pooling, a diagnosis guide, and a 40% runtime improvement lesson.
Implement ADR Management Using Agentic AI:
Traditional ADR processes are manual and often skipped. With agentic AI, ADRs become an automated knowledge system—capturing decisions, linking them to code and systems, and making them instantly searchable. This turns institutional knowledge into a strategic advantage for modernization and operational excellence.
Five-Agent ADR System:
- Decision Detection: Spots new decisions from code changes, design docs, or discussions.
- Context Analysis: Pulls in dossiers, tribal knowledge, and compliance data to build full decision context.
- ADR Drafting: Creates structured ADRs with links to code, alternatives, and predicted impacts.
- Validation: Checks completeness, conflicts, and consistency before review.
- Review Orchestration: Routes to stakeholders, manages deadlines, and finalizes ADRs with an audit trail.
4.3. Layer 3: Intelligent Orchestration (AI Planning Brain):
Layer 3 is the thinking layer that transforms human questions into smart, executable plans.
Core Architecture Components:
4.3.1. Query Processing Engine (Entry Point)
This is the entry point that turns natural language questions into structured, actionable plans.
How it works:
- Understands intent: Detects goals like cost reduction or performance improvement.
- Extracts details: Identifies systems, timeframes, metrics, and constraints.
- Structures the query: Defines objectives, scope, success criteria, and urgency.
Example:
Raw query: “We need to cut MSU costs by 20% next quarter without impacting customer service.”
→ Structured output:
Cost optimization, target = 20% reduction, timeframe = Q4 2025, constraint = no service impact, priority = high.
4.3.2. Context Builder (Knowledge Integration Engine)
The Context Builder is the system’s memory interface. It pulls knowledge from Layer 2 and turns it into context for smarter decisions, bringing decades of organizational wisdom to current challenges.
Sources of Knowledge:
- Graph Database (Structural): Captures dependencies, ownership, ADR links, and historical patterns.
- RAG Database (Experiential): Adds tribal knowledge, lessons learned, best practices, and risk patterns.
- System Dossiers (Operational): Provides live metrics, recent changes, business impact, and technical constraints.
Unified Context Generation:
By combining these sources, the Context Builder delivers:
- Opportunity Analysis: Where improvements are possible.
- Constraint Mapping: Technical, business, or regulatory limits.
- Risk Assessment: Likelihood and impact of failures.
- Resource Needs: Skills and capabilities required for success.
Sample Example :
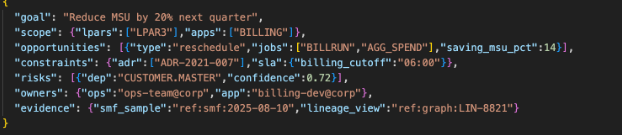
4.3.3. Roadmap Generator (Strategic Planning Engine)
The Roadmap Generator converts business objectives and system context into executable modernization plans. Each plan is structured to be practical, phased, and risk-aware.
Key Functions:
- Current vs. Target State: Compares today’s systems with the desired end state, highlighting gaps and the most feasible paths forward.
- Phased Execution: Breaks large initiatives into smaller, logical phases that deliver incremental value, maintain business continuity, and allow adjustments along the way.
- Risk & Success Framework: Identifies potential risks, defines mitigation strategies, and sets measurable success criteria with milestones and checkpoints.
By combining these elements, the Roadmap Generator ensures every strategy is grounded in reality, executable with available resources, and aligned with organizational goals and institutional knowledge.

4.3.4.Hybrid MCP Orchestrator (Intelligent Agent Selection)
The MCP server is the smart traffic director that connects plans to the right agents. This is where the roadmap becomes a DAG of executable tasks in JSON.
Each node = a task with type, inputs, deps, risk, approval rules.
Sample Example:

The Hybrid MCP Orchestrator represents a sophisticated agent selection system that balances reliability with intelligence, ensuring both operational safety and strategic flexibility in mainframe operations.
Routing (Policy Router vs LLM Planner)
- For each task in the DAG:
– Policy Router (80%): If the task matches a known capability + safe policy, route directly to the right agent.
– LLM Planner (20%): If the task is complex/novel, the LLM helps decompose it into sub-tasks (still JSON nodes in the DAG).
Plan Validator
- Validates the whole DAG (schema, acyclic, RBAC, policies).
- Ensures tasks are safe before execution.
4.3. Layer 4: Agent Orchestration (Specialized Intelligence Network):
Layer 4 is the “action layer” where specialized AI agents turn plans into real actions, each focused on a distinct outcome.
MCP walks the DAG in order, invoking the right specialized agent for each task.
Specialized Agent Network Architecture
Cost Intelligence Agent
- Focus: Reduce MSU costs, eliminate waste, and maximize ROI.
- Capabilities: Predictive modeling, workload optimization, ROI calculations, and cost-risk analysis.
- Example Outcome: Rescheduling 12 batch jobs to off-peak hours → $340K annual savings.
Performance & Impact Agent
- Focus: Improve response times, plan capacity, and evaluate system impacts.
- Capabilities: Real-time monitoring, bottleneck detection, “what-if” simulations, and SLA management.
- Example Outcome: Database buffer pool optimization → 25% I/O reduction.
Modernization Agent
- Focus: Build modernization strategies, manage risks, and automate where possible.
- Capabilities: Complexity scoring, strategy selection (rehost/replatform/refactor/replace), phased planning, and automation.
- Example Outcome: PAYROLL app scored 6.8/10 → Refactor recommended with automated Java microservice generation.
Operational Control Agent:
- Focus: Optimize workload scheduling, orchestration, and resource efficiency.
- Capabilities: Intelligent scheduling, load balancing, and operational automation.
- Example Outcome: Automated incident escalation → MTTR reduced by 60%.
5. Summary
This project introduces a four-layer agentic AI architecture that turns mainframes into self-aware, self-optimizing platforms.
- Layer 1: Interface & Session – A secure, omnichannel gateway (web, CLI, chat, API) with contextual sessions.
- Layer 2: Knowledge Intelligence – Builds institutional memory through a knowledge graph, semantic search, and ADR management.
- Layer 3: Intelligent Orchestration – Interprets natural queries, assembles context, and generates risk-aware roadmaps.
- Layer 4: Agent Orchestration – Executes plans with specialized agents for cost, performance, modernization, and operations.
Together, these layers automate decision capture, validation, and execution—making modernization continuous, measurable, and safe. Organizations gain instant insights, proactive cost savings, and faster evolution without sacrificing reliability or compliance.
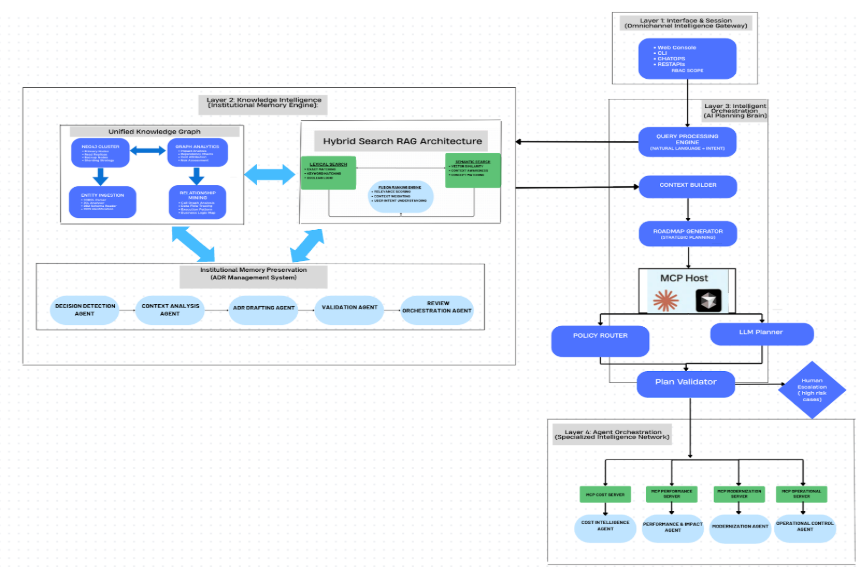
Fig: Overview of the Architecture including all the layer
Reflections and Learnings:
Through this mentorship with the Open Mainframe Project, I gained a deeper understanding of how mainframes work and the challenges of modernizing such critical systems.Learning about COBOL, JCL, SMF data, and operational pipelines gave me an appreciation for their scale, reliability, and complexity.
One of the key insights was the importance of governance. I realized that modernization is not only about automation or orchestration—it is about building trust. Issues such as missing ADRs and the need for human-in-loop validation showed that safety and governance must be designed into the architecture from the beginning
Another challenge was the parser complexity. Extracting reliable metadata from COBOL, JCL, and DB2 systems proved to be much harder than expected. I learned the importance of combining static parsing with runtime traces to get a fuller, more accurate picture of system behavior. This shaped my appreciation for dual-source reconciliation and knowledge graphs.
This mentorship helped me develop skills in thinking architecturally, layering systems for clarity, and balancing automation with safety. It also improved my ability to present complex technical ideas in a structured and accessible way.
Overall, I focused on understanding mainframes, identifying modernization challenges, and shaping architectural strategies. The key takeaway for me is the mindset required for modernization: balancing innovation with safety, automation with governance, and technical depth with clarity.