
Open Mainframe Project Summer Mentorship Series: Midterm Updates – At this midpoint, our selected mentees are reporting in. Below, you’ll learn what they’ve built, the challenges they’ve overcome, and their goals for the rest of the summer. We’re proud of every contribution and eager to see what comes next. Hear from A.Vijay Aditya, Indian Institute of Technology (BHU), Varanasi.
Mainframe systems power some of the most mission-critical workloads across industries like banking, insurance, and government. However, maintaining these legacy systems is becoming increasingly expensive due to aging technology, lack of skilled developers, and outdated programming languages. To tackle this, organizations are adopting AI-driven modernization pipelines that automate discovery, analysis, decision-making, and transformation of legacy applications.
This blog introduces a structured, multi-agent approach to automate mainframe modernization and optimize costs:
Mainframe application discovery and Analysis:
Before any modernization work can begin, organizations must first understand what exists inside the mainframe. This includes identifying COBOL programs, JCL scripts, datasets, copybooks, VSAM files, and more. This process, called discovery, is often manual and tedious. The Discovery Agent automates this step using existing mainframe utilities and APIs, extracting all relevant information for further analysis.
Agent 1 – Discovery Agent:
The Discovery Agent is the foundational AI component in a mainframe modernization pipeline. It automates the tedious, manual process of inventorying legacy applications by using native mainframe tools and secure data transfer methods.
1. Connect to Mainframe
- Use a terminal emulator like IBM PCOMM, x3270, or TN3270 to connect to the z/OS system via TSO(Time Sharing Option).
2. Use mainframe utilities to list datasets and discover applications:
| Tool | Purpose | Working |
| IEHLIST | Lists PDS/PDSE members and Volume Table of Contents (VTOC) entries | Used to list datasets and directories within partitioned datasets. Helpful in examining the contents of COBOL sources, copybooks, etc. |
| IDCAMS | Lists and manages VSAM datasets and system catalogs | Used to access and manage catalog entries and VSAM dataset structures. Essential for identifying structured data schemas and transactional data. |
| ISPF 3.4 | Manual dataset browsing via TSO interface | Helpful during setup and validation. Allows developers to manually inspect the dataset structure and filter the dataset names interactively. |
| z/OSMF REST APIs | Enables automated dataset discovery using REST endpoints | Allows programmatic access to dataset metadata and content remotely. Ideal for integrating into AI agents. |

This helps to extract all the relevant datasets like :
- COBOL, PL/I, Assembler source code
- JCL scripts (e.g., SYS1.JCL.LIB)
- Copybooks (e.g., SYS1.CPYLIB)
- DB2/VSAM/IMS schemas (e.g., SYS1.DBDLIB)
- BMS screen definitions
- Security logs (SMF, SDSF)
- Transactional programs (CICS modules)
3. Methods to extract the Data:
| Method | Use Case |
| FTP | Transfer datasets from mainframe to PC or local VM over TCP/IP. Used in scripts and batch jobs. |
| IND$FILE | Transfers files using 3270 terminal emulators like x3270. Ideal for quick file transfers from a TSO session. |
| z/OSMF REST API | Provides secure RESTful access to datasets, supports both metadata browsing and downloading files. |
4. Parsing & Preprocessing:
After extracting the raw datasets from the mainframe (using tools like FTP, IND$FILE, or z/OSMF REST APIs), the Discovery Agent performs parsing and preprocessing to make the data usable for AI-driven analysis.
4.1. Parsing COBOL, JCL, and Copybooks:
Use custom or open-source parsers (like COBOL-Parser, ANTLR COBOL grammar) to tokenize and analyze each COBOL file.
- Break the code into tokens (e.g., keywords, variable declarations, data definitions)
- Extract PERFORM, CALL, IF, MOVE, OPEN, and CLOSE statements
- Map out control flow and subroutine calls
4.2. Extracting Metadata:
- For JCL: Parse EXEC, DD, and JOB statements to understand job flow and data usage.
- For Copybooks: Identify common data definitions (01, 05 levels) reused across multiple programs.
- For VSAM: Extract key field definitions and dataset references.
4.3. Dependency Mapping:
- Match programs to the copybooks they include
- Identify batch jobs referencing VSAM/DB2 tables
- Create call graphs: which programs call which others
4.4. Parse SMF/SDSF Logs:
Understand application runtime behavior and costs.
- From SMF Type 30/70/110: Extract job execution time, CPU usage, number of runs, abends
- From SDSF logs: Pull job status (completed, abended), frequency, errors.
4.5. Generate Dependency Graphs
Map how programs and datasets are linked.
- Trace calls between COBOL programs (CALL), and JCL→Program→Dataset chains.
- Use tools like NetworkX (Python) to visualize and store graphs.
4.6. Compute Technical Complexity:
Quantify how difficult modernization will be.
Metrics:
- Lines of Code (LOC)
- Cyclomatic complexity (number of branches)
- Copybook count
- Fan-in/Fan-out (program coupling)
4.7. Normalize and Package as JSON
Structure all parsed and enriched data into a machine-readable format for the Analysis Agent. Once parsing is complete, all extracted metadata is saved in a structured JSON format. This becomes the input to the Analysis Agent.
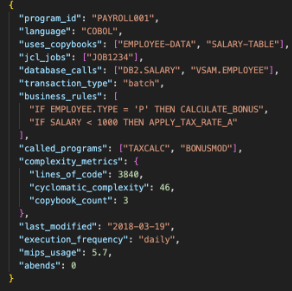
Fig 1 : Sample output Schema for the Discovery agent

Fig : Architecture of the discovery agent
Agent 2 – Analysis Agent:
The Analysis Agent consumes the parsed metadata from the Discovery Agent and performs intelligent scoring and ranking using LLMs, rule-based logic, and usage metrics.
Step 1: Source Code Metrics
Extract from COBOL, PL/I, or Assembler files using static analysis or LLMs.
| Metrics |
|
|
||||
| MIPS usage | SMF Type 30/70 logs | CPU cost per program
Higher MIPS = More expensive to run. |
||||
| Execution frequency | SMF logs / JCL job triggers | How often does it run
More frequent = higher total cost. |
||||
| Dataset size | IDCAMS / z/OSMF metadata | Disk/storage cost
Higher size = More storage cost. |
||||
| Aging components | last_modified from code parsing | Flags outdated programs
Very old code is riskier and costlier to maintain. Add an Aging_penalty if the code is old (say, more than 5 years) |
Cost Score Formula : mips_usage × frequency_multiplier + (dataset_size_mb / 100 ) + aging_penalty
Step 2 : Business Value Estimation
- Identify programs involved in mission-critical business logic
- Flag programs that handle sensitive data
- Determine usage relevance based on dependencies and frequency
- Give a numerical business value score (0 to 10)
What the Agent Looks At:
1. Business Rule Mining from COBOL
- Use LLMs (e.g., Code LLaMA, Mistral) with prompts like, for example :
“Explain the business purpose of this code:
IF EMPLOYEE.TYPE = ‘P’ THEN CALCULATE_BONUS”.
- This reveals:
-
- Whether the logic belongs to key domains like for example : Payroll, Insurance, LoanApproval.
- The intent of the program, even if the naming is ambiguous.
Example Insight:
IF EMPLOYEE.TYPE = ‘P’ THEN CALCULATE_BONUS
(Means the app handles payroll bonuses → High business value)
2. Sensitive Dataset Detection:
In mainframe modernization, one of the key factors that influences whether an application should be prioritized for modernization is how sensitive the data it accesses is. Applications that handle personally identifiable information (PII) or financial data are generally considered business-critical, and their modernization needs to be handled carefully, securely, and often urgently.
For example :
If the Discovery Agent output includes fields like (in JSON):
“database_calls”: [“DB2.EMPLOYEES”, “VSAM.SALARY”]
- You can infer that it accesses salary or PII data.
- We mark such applications with high business sensitivity
3. Dependency Check / Program Fan-In
Count how many other programs call this one:
“called_by”: [“REPORTGEN”, “HRMODULE”]
- More incoming calls = higher business utility.
4. Usage Frequency
Already captured via:
“execution_frequency”: “daily”
- Daily programs typically = operational backbone.
Business Value Scoring Formula
score = w1 * is_critical_rule + w2 * is_sensitive_data +
w3 * frequency_multiplier + w4 * dependency_count
You can normalize this to a 0–10 scale per application.
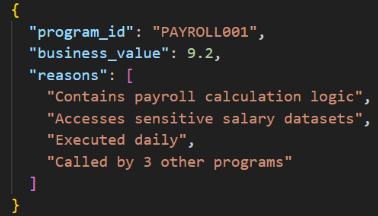
Fig 2 : Sample output Schema for Analysis agent
Step 3: Complexity Scoring – Step-by-Step
Goal:
Assign a complexity score (0–10) to each application based on its structure and technical depth. This score influences whether the app should be:
- Rehosted (low complexity)
- Refactored (moderate complexity)
- Rewritten (very high complexity)
Formula:
Complexity Score = w1 * LOC + w2 * Cyclomatic + w3 * Copybooks + w4 * Fan-Out
Where:
- w1, w2, w3, w4 are weights to control the importance of each metric
(e.g., w1 = 0.25, w2 = 0.4, w3 = 0.2, w4 = 0.15) - The raw values are normalized (0–10 scale) before applying weights
Example Thresholds for Normalization:
| Metric | Normalization Logic |
|---|---|
| Lines of Code (LOC) | LOC / 10,000 (capped at 10) |
| Cyclomatic Complexity | complexity / 50 (capped at 10) |
| Copybook Count | count / 10 (capped at 10) |
| Fan-Out / Call Depth | depth / 5 (capped at 10) |
Example Calculation
Content of the program.json file :
{
“lines_of_code”: 3840,
“cyclomatic_complexity”: 46,
“copybook_count”: 4,
“fan_out”: 3
}
Normalize:
- LOC: 3840 / 10000 ≈ 0.384
- Cyclomatic: 46 / 50 ≈ 0.92
- Copybooks: 4 / 10 = 0.4
- Fan-out: 3 / 5 = 0.6
Apply weights (w1=0.25, w2=0.4, w3=0.2, w4=0.15):
Complexity Score = 0.25 * 0.384 + 0.4 * 0.92 + 0.2 * 0.4 + 0.15 * 0.6
= 0.096 + 0.368 + 0.08 + 0.09 = 0.634 → Scaled to 6.34 / 10
So, the app has a moderate-to-high complexity → may be tagged as “Refactor”.
Output:
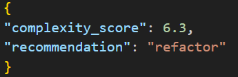
Fig 3 : Sample output Schema
Step 4 : Application Ranking & Tagging
Goal:
The Analysis Agent ranks and tags each application into one of four modernization categories:
- Modernize Now
- Refactor
- Rehost
- Retire
This classification simplifies decision-making and enables downstream agents to focus only on the most important applications.
Tagging Logic:
Each app is scored on a combination of:
- Business Value (0–10)
- Complexity Score (0–10)
- Cost Estimate (numeric or scaled)
- Execution Frequency (e.g., daily, monthly)
Then it is tagged using business rules like:
| Condition | Tag |
| High value (>7), high cost, frequent use, moderate complexity | Modernize Now |
| High value, high complexity (>6), moderate cost | Refactor |
| Moderate value (3–7), low complexity, high cost | Rehost |
| Low value (≤2), low frequency, old last modified, low complexity | Retire |
Final Output Schema:

Fig 4 : Sample output Schema
For another program:

Fig 5 : Sample output Schema
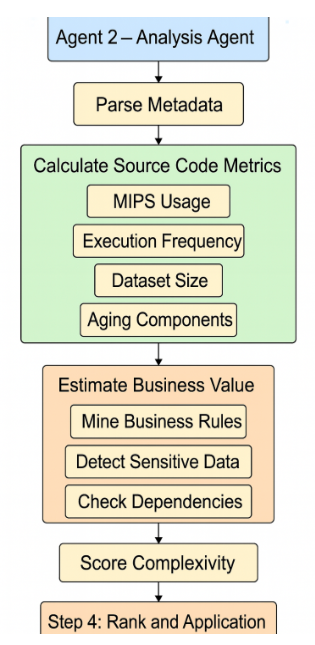
Fig 2 : Architecture of Analysis Agent
Agent 3 – Roadmap Generator
Goal:
To generate custom modernization roadmaps for only those applications that are:
- Costly
- Complex
- Business-critical
Step 1: Filter Only Modernize-Worthy Apps
Apply filters like:
if modernization_score > 7.5 and business_value > 8.0:
shortlist_for_roadmap = True
Step 2: Group Apps by Recommendation
Create separate treatment paths for:
| Recommendation | Strategy |
| refactor | Code transformation with logic retention |
| rehost | Lift-and-shift to cloud or containers |
| rewrite | Full redesign using modern stack |
| retire | Document and decommission safely |
Step 3: Fetch Source Artifacts
- Pull relevant code artifacts (COBOL, JCL, copybooks)
- Access associated database schemas, e.g.:
- DB2 DDL scripts
- VSAM definitions
- IMS hierarchical schemas
These can be extracted from earlier Discovery Agent stages and stored in a local folder or vector store.
Step 4: Load into Vector DB (for RAG)
Use a vector database (e.g. FAISS, ChromaDB) to store:
- Code snippets (functions, modules)
- Business rules (from COBOL)
- JCL job steps
- Database structures (table schemas, keys, constraints)
Step 5: Prompt the LLM via RAG
The prompt now includes:
You are a COBOL modernization expert.
Here is the parsed code of PAYROLL001 and its related DB2 schema.
This app is marked for refactor (Score: 9.1).
Based on the dependency depth, MIPS cost, and code structure, generate a phased roadmap to refactor this application safely.
RAG will enrich the prompt with:
- Extracted business rules (IF EMP.TYPE = “P” THEN…)
- Schema relationships (foreign keys, VSAM file mappings)
- JCL job dependencies
Step 6: Output a Detailed Roadmap (in JSON / Markdown)

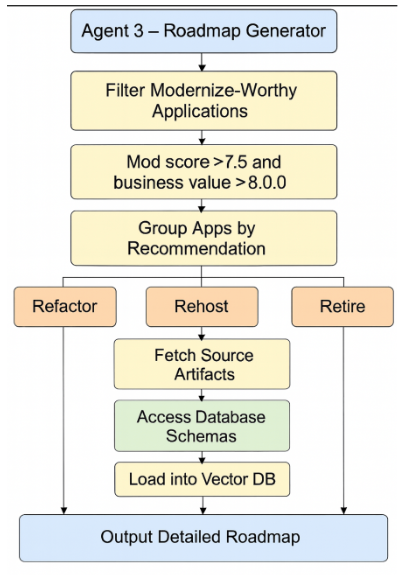
Fig : Architecture of Roadmap Generator Agent
Agent 4- Modernization Executor
Goal
Automate the transformation, code generation, and testing process using the roadmap + access to actual source code and databases.
1. From Discovery Agent Outputs
All the code assets were already extracted by the Discovery Agent using tools like:
| Source | Example Output | Extraction Method |
| COBOL programs | SYS1.COBOL.SOURCE | via FTP / IND$FILE / z/OSMF |
| JCL scripts | SYS1.JCL.LIB | via FTP or IND$FILE |
| Copybooks | SYS1.CPYLIB | via FTP or IND$FILE |
| DB schemas | SYS1.DBDLIB, VSAM mappings | via IDCAMS, parsed manually |
These files are now stored in your PC or cloud VM, usually in:
- A local directory structure:
./discovered_assets/COBOL/, ./discovered_assets/JCL/ - OR a metadata database (like SQLite/NoSQL)
- OR vector store (like FAISS/ChromaDB for RAG)
2. Code Understanding via LLM (Contextual RAG):
Feed both roadmap + code context into the LLM using a Retrieval-Augmented Generation (RAG) approach.
Use a hybrid prompt:
For example :
“Based on the roadmap for PAYROLL001, refactor the COBOL logic to a Java microservice using REST architecture. Here’s the original code + copybooks.”
LLM reads:
- Legacy COBOL logic (with copybooks resolved)
- Data source references (VSAM, DB2)
- JCL entry point for batch or transactional execution
This step helps the model understand what transformation is required.
3. Code Generation
LLM generates:
- Java/Python/C# source code
- API controllers (if modernized into microservices)
- Entity classes or DTOs mapped from copybook fields
- DB Access layer (e.g., using JPA/Hibernate for DB2)
4. Auto-Test Creation
For each generated module:
- Generate test cases (e.g., JUnit, PyTest)
- Include edge-case tests (e.g., null checks, max length fields)
- Simulate integration with dummy DB or mock endpoints
5. Run & Validate in Sandbox
Use CI/CD runner (e.g., GitHub Actions + Docker) to:
- Compile code
- Run unit tests
- Log results
6. Failure Handling and Feedback Loop
If test fails:
- Capture test logs
- Prompt LLM:
For example :
“Fix this error in method calculateBonus() — java.lang.NullPointerException” - LLM refactors and re-tests until test passes.
Technologies Used:
- LLM: Claude, GPT-4, StarCoder, Deepseek R1
- Code interpreter: OpenAI Python tool / Codeium
- Vector DB: FAISS / Chroma
- CI/CD: GitHub Actions, Docker, PyTest/JUnit
- LangChain: For chaining prompts and transformation logic
- CrewAI / LangGraph: For orchestrating code generation, testing, and debugging agents
- Dust / AutoGen / SemanticRouter: For task routing and LLM-test loop feedback
- GitHub Copilot / VS Code API: For embedding suggestions and tests directly in IDE
Conclusion:
During the first half of this project, I focused on understanding the fundamental architecture and operational workflow of mainframe systems. I extensively studied how legacy applications are structured (e.g., COBOL, JCL, VSAM), how they interact with datasets and transaction managers like CICS, and the types of metadata and logs available within the mainframe environment.
Building on this understanding, I designed a multi-agent architecture for automating mainframe modernization using AI. This architecture includes four AI agents: Discovery, Analysis, Roadmap Generation, and Modernization Execution—each targeting a specific phase of the modernization lifecycle. These designs were inspired by a combination of existing mainframe documentation and modern AI-driven automation strategies, especially leveraging LLMs, RAG pipelines, and vector databases for intelligent transformation.
So far, my work has been conceptual and architectural. The second phase of the project will focus on implementing and validating this architecture through prototypes, automation workflows, and proof-of-concept testing and also developing this architecture .
The goal is to move from theoretical design to a demonstrable system that automates code understanding, transformation, and testing—ultimately optimizing mainframe costs through targeted modernization.
References :
https://www.geeksforgeeks.org/computer-networks/file-transfer-protocol-ftp-in-application-layer/
https://docs.zowe.org/stable/web_help/index.html?p=zowe_zos-files_download_data-set
https://www.geeksforgeeks.org/dbms/job-control-language-jcl-utilities/
https://www.mainframestechhelp.com/utilities/idcams/listcat.htm
https://www.ibm.com/docs/en/zos/2.4.0?topic=guide-using-zosmf-rest-services
https://www.ibm.com/docs/en/zos/3.1.0?topic=3-data-set-list-utility-option-34
https://wearecommunity.io/communities/india-devtestsecops-community/articles/1243