
This summer, I had the chance to dive into a project that combined both my interests and a real-world challenge: porting a high-performance math library – BLIS to z/OS. When I first joined the Open Mainframe Project Mentorship program under the zopen community, I expected to learn about new tools and systems, but I didn’t anticipate just how much of an impact this work would have on the performance of AI workloads on the mainframe. My name is Jerry Sun, and I am a fourth year computer engineering student from the University of British Columbia. For a quick recap of the midterm progress, where I explained some of the challenges I faced when porting BLIS to z/OS, follow this link. You can also check out the source code and build details in my blisport repository.
Watch my final presentation here:
Why Port BLIS to z/OS?
The main motivation for this project was to enable integration with llama.cpp, a popular open-source framework for running inference on large language models efficiently. llama.cpp relies heavily on fast and reliable BLAS routines, and BLIS is a natural fit because of its flexibility, modular design, and performance.
By porting BLIS to z/OS, we can leverage optimized kernels that accelerate operations like matrix multiplications and tensor computations. This unlocks several key benefits:
- Performance gains: Faster matrix operations with reduced latency and improved throughput for AI workloads.
- Better hardware utilization: BLIS helps take advantage of the full capabilities of z/OS CPUs.
- Strategic value: With BLIS available, modern AI frameworks can run more efficiently on enterprise systems, bridging the gap between high-performance computing and mission-critical business environments.
In short, the port makes z/OS not just compatible with these AI workloads, but capable of running them at a much higher level of efficiency.
Overcoming Challenges
Porting BLIS was far from straightforward. The toughest issue came when upgrading to BLIS 2.0: a testsuite runtime crash. At first, I felt lost in the massive codebase, even after scattering printfs across the code. The turning point came when my mentor introduced me to compiler tracing with Clang, which conveniently supports with a single flag (zopen build -instrument). This produced detailed runtime traces of function calls and memory allocations. With the help of AI tools, I was able to trace the crash back to its root cause and resolve it. A variable was left uninitialized in one of the thread initialization procedures. This leads to undefined behavior. Since this contribution is not specific to z/OS, I created a patch for the issue and created a PR to the upstream repository.
This experience not only solved the immediate problem, but also gave me a powerful new way to debug large-scale projects on z/OS.
Evaluating BLAS vs. Plain CPU Execution for Gemma3 1B Q8_0
When working with large language models, inference performance can vary significantly depending on the backend used for matrix operations. Our baseline for the evaluation is the current llamacpp, which relies on plain CPU. We tested across multiple benchmarks designed to measure both prompt processing (pp) and token generation (tg), under both single-thread and two-thread configurations.
Benchmark
We used four evaluation setup:
- Prompt Processing (pp)
- pp64: smaller prompt size
- pp512: larger prompt size
- Token Generation (tg)
- tg16: small number of generations
- tg128: larger number of generations
The throughput is measured in tokens per seconds (t/s).
Results
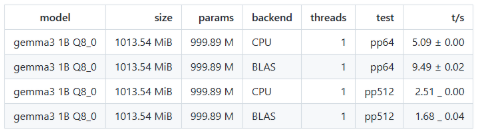
On pp64, BLAS delivered a huge 86% increase in throughput compared to plain CPU. However, on pp512, performance dropped by ~33% with BLAS, suggesting that overhead outweighs benefits on larger prompts. BLAS is beneficial for smaller prompt workloads, but may hurt performance when prompts get larger.
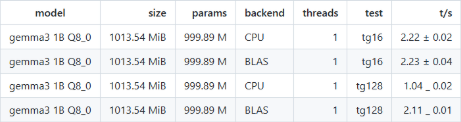
On tg16, performance was essentially the same between CPU and BLAS. On tg128, BLAS showed over 2× improvement, nearly doubling token generation speed. This trend was consistent with what we also observed during inference runs using llama-cli. For longer generations, BLAS provides massive speedups, while for short runs the CPU is just as effective.
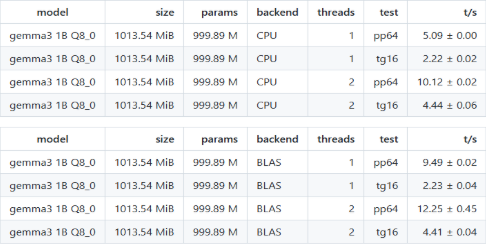
We also tested both single-thread and two-thread setups, focusing on pp64 and tg16. As expected, increasing threads naturally improved throughput for both CPU and BLAS. However, the relative benefit of BLAS decreased with more threads, since CPU parallelism already delivers significant gains.
Overall, the results clearly demonstrate the performance gains of llama.cpp with BLAS. These improvements were not only evident in the benchmarks but also confirmed during real inference runs with llama-cli (as shown in the presentation), where longer generations consistently showed substantial benefits from BLAS optimization.
Reflections
This mentorship has been a period of intense growth. I learned not only about the technical aspects of porting and performance optimization, but also about collaboration in open source. Contributing to the zopen community gave me insight into how shared tools and collective effort can transform entire platforms. I am deeply grateful to my mentor Igor Todorovski for his patience, guidance, and encouragement throughout this summer.
Next Steps
One promising direction to further improve the performance of BLIS on z/OS is the integration of hardware-specific optimized kernels. These kernels are hand-tuned to take full advantage of a processor’s unique instruction set and capabilities. You can find more details about BLIS hardware optimization kernels here. Adopting it for z/OS could unlock significant performance gains, enabling BLIS to better utilize the underlying hardware. This would further establish z/OS as a strong platform for running modern AI and scientific computing workloads.
Looking Ahead
Although this mentorship has concluded, my journey with open source is only beginning. I look forward to continuing my contributions to the open-source community as a whole. This experience has shown me the impact that even a small contribution can have when it’s part of a global open-source ecosystem, and I’m excited to keep building on that.