
Hey there, I’m Advith Krishnan, an AI engineer and researcher, and this post wraps up my Linux Foundation mentorship with the Open Mainframe Project (Modernization Working Group). This summer, I had the privilege to work on the “RAG to Riches” project under the mentorship of Dr. Vinu Russell Viswasadhas. This report combines both my midterm updates and final-term progress, showcasing how the project evolved from architectural design to a working prototype, and what I’ve learned throughout the journey.
Problem Statement
In large organizations, the most valuable business insights are often the hardest to access. They are buried deep within mainframe archives, siloed log systems, or schema-heavy SQL tables. Yet this hidden knowledge can provide insights useful for preemptive problem identification, optimizing maintenance timelines and understanding data trends.
The challenge? Making sense of vast, heterogeneous data across a system or infrastructure and finding relevant associations across them. That’s the problem I tackled with RAG to Riches by building a layered framework to unify data access and surface contextual answers via LLM-powered retrieval. The project goal was to design and test a Retrieval-Augmented Generation (RAG) framework that bridges the gap between mainframe systems, modern observability systems and natural language querying, making it possible to get relevant answers to user queries like the following:
- “Why did our login services degrade last Friday?”
- “Which user sessions are at risk based on I/O trends?”
- “Show anomalies across IMS and cloud metrics for last quarter.”
Midterm Progress: Designing the Framework
During the first half of the mentorship, my mentor and I focused heavily on system architecture ideation. We studied existing methods, identified their limitations, and iterated toward a multi-layered design.
Some of the key design considerations were as follows:
- Who is this system for?
Originally targeted at sysadmins and infrastructure architects, we realized its scope extends to analysts, compliance officers, and support teams. This widened scope pushed us toward a Query Understanding Layer (QUL) and Query Planner for generalized intent handling. - How do we retrieve massive data slices from mainframes?
We proposed a dual-stage retrieval strategy:- Level-1: Cached retrieval from a Vector Knowledge Graph (VKG).
- Level-2: Deeper semantic + structured retrieval via connectors when cache misses.
- How do we dynamically plan retrieval paths?
We envisioned the Query Planner to execute depending on query type, source, and permissions, ensuring flexibility and RBAC enforcement.
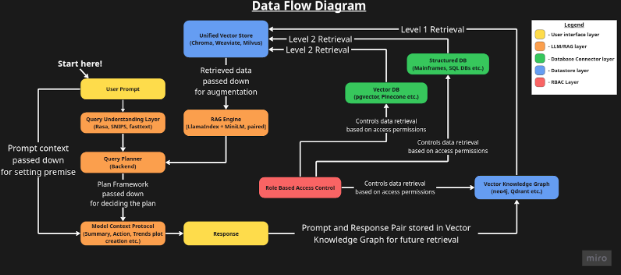
The resulting multi-layered architecture we devised included:
- Query Understanding Layer (QUL) – Classifies prompt type, extracts entities, infers intent.
- Query Planner – Creates an execution plan.
- RAG Engine – Handles L1/L2 retrieval.
- Model Context Protocol (MCP) – Assembles context, orchestrates actions/tools.
- Vector Knowledge Graph (VKG) – Stores embeddings for fast retrieval and creating cross-data connections.
- Database Connector Layer – Interfaces to DB2, IMS, PostgreSQL, Splunk, etc.
- RBAC Middleware – Enforces secure, scoped access.
By midterm, we had an architectural blueprint, clear prompt/data flows, and a prioritized implementation plan. The following diagram demonstrates what we envisioned in a visual manner:
Final-Term Progress: From Design to Prototype
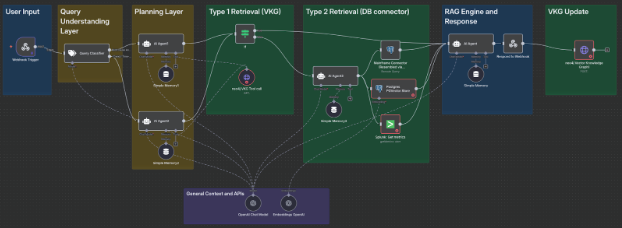
In the second half of the mentorship, I moved from design to implementation. The full production system will require multiple data connectors with different mainframe and modern data storages, RBAC Middleware and MCP integration. For the benefit of the implementation, the constrained timeline and the lack of available emulators, Dr. Vinu and I agreed at the beginning of the project to assume a working integration with a mainframe via a structured DB integration as a proxy for emulating mainframe data retrieval. I implemented a functional proof-of-concept in n8n that validates the original framework design with the following workflow:
- Query Input where the user submits a question through a webhook/chat UI, triggering the framework
- Query Understanding Layer which classifies the query type (trend, metric, root cause etc.) and passes the user input into the according flow.
- Query Planner which creates a plan based on the user input and query type that contains DB queries, list of data required and so on.
- Connector Layer which used n8n’s database connectors (Postgres, JSON logs) to emulate mainframe data sources (SMF-like logs, IMS/DB2 datasets) for the purpose of demonstration. However, it is possible to integrate actual mainframes via the development of custom API interfaces.
- Dual-Stage Retrieval system which contains two levels of retrieval (Level-1 / Level-2) where Level-1 is a Vector Knowledge Graph lookup for cached queries and Level-2 is meant for deeper semantic + structured querying via connector layer if cache misses.
- RAG Engine which bundles retrieved chunks + user query for grounded natural language response synthesis.
- Response + Knowledge Graph Update where the final answer is sent back via webhook/UI response and the query + evidence is stored into the vector knowledge graph for future reuse.
Following shows the implemented workflow via n8n:
This layered architecture setup demonstrates and validates exactly what our whitepaper will propose. It is currently undergoing peer review for fine-tuning towards a valuable and well-written publication to introduce the RAG to Riches framework.
What I Learned
This mentorship has been a transformative experience for me and some of my biggest takeaways include the following:
-
- Architecture-first thinking: I learned how to break down an abstract vision into layered, modular components that can evolve independently.
- Trade-offs in retrieval systems: Balancing speed (cache) vs. specificity (deep retrieval) is not just technical, but also a user experience problem that requires consideration.
- Low-code demos are helpful for validation: Tools like n8n make it possible to prototype complex AI architectures quickly, validating ideas before deep engineering.
- Mentorship matters: My mentor, Dr. Vinu Russell Viswasadhas, not only guided the technical journey but also helped me sharpen my ability to ask the right design questions.
- Start small and expand: Despite having an abundance in integration possibilities, I learnt to prioritize building a basic framework and not cloud my implementation plans with every idea that comes to mind.
Conclusion
The RAG to Riches framework now exists as a validated proof-of-concept, with a clear architecture and a working proof-of-concept implementation that can be scaled for larger, more complex systems. This prototype demonstrated that the framework can bridge heterogeneous data sources and deliver contextual answers in natural language, thereby directly contributing to the mentorship goal.
The journey from midterm ideation to final implementation has been an invaluable learning experience in systems design, retrieval-augmented generation, and hybrid data integration. I look forward to continuing this work by adding connectors to real mainframes, optimizing retrieval, and further contributing back to the Open Mainframe Project’s Modernization Working Group.