
Written by Prince Singh, Open Mainframe Project 2023 Summer Mentee and postgraduate student at the Indian Institute of Information Technology

The Open Mainframe Project’s Software Discovery Tool mentorship team this past summer which includes me, my fellow mentee, Aashish Khatri and mentors Elizabeth Joseph and Arsh Pratap, we offer a one-stop solution for people who browse different websites to find packages they can work out with. Don’t worry we’re here for you! Continue reading and watch the short recap video below:
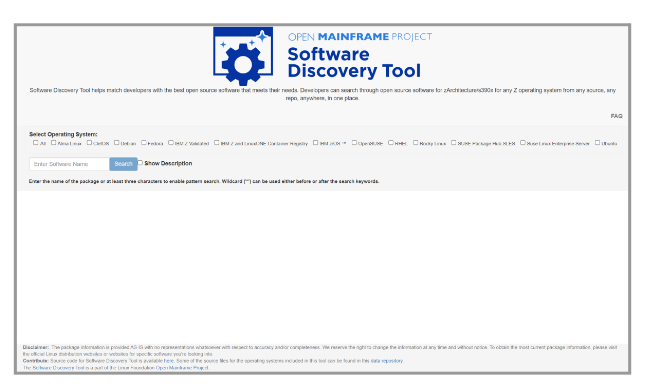
The Software Discovery Tool (SDT) is an online search tool for Linux distributions and other software sources that support the s390x (IBM Z) hardware architecture. The tool is getting bigger and bigger with time, offering a wide variety of distributions to choose from.
The tool presents a web UI for searching and allows you to select from various Linux distributions and other software sources. We manage JSON files in our data repository that lists the software, along with optional descriptions and version numbers. Why the version number? As an individual who is used to working on various platforms, it’s a boon to keep in mind which platform gives you the latest version of the searchable software. When in doubt, we also have an FAQ section from where users can get information on the source of the package lists and what more can be expected from us in the near future of the tool.
 In our mentorship, the core task that our mentors want to see completed is the implementation of the MySQL back-end, which was until then in the “proposed” state and needs to be reviewed and tested for robustness. Some administration and deployment of the tool in production also needed to be automated further, as some of that was still a manual process for the version in production. Finally, there were also UI improvements needed for the tool to address common pain points. I was mainly assigned to the MySQL back-end section, and Aashish Khatri was resolving front-end issues.
In our mentorship, the core task that our mentors want to see completed is the implementation of the MySQL back-end, which was until then in the “proposed” state and needs to be reviewed and tested for robustness. Some administration and deployment of the tool in production also needed to be automated further, as some of that was still a manual process for the version in production. Finally, there were also UI improvements needed for the tool to address common pain points. I was mainly assigned to the MySQL back-end section, and Aashish Khatri was resolving front-end issues.
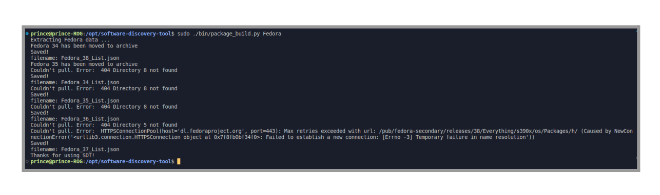
During this mentorship, I actively contributed to our core and data repositories by raising a total of 9 issues and submitting 24 pull requests. One of the first and major issues that I raised was when I was looking through the code for package build, I noticed that while creating packages for a Fedora version, we were saving them in a file with an index lower than what we were searching for. For example, packages of Fedora 34 are saved in the Fedora 38 JSON file, Fedora 35 packages are saved in the Fedora 34 JSON file and so on.
Discovering this error was a rewarding experience, as it marked my independent achievement and marked the beginning of my contributions to the project.
Some of my favorite contributions that I’ve made so far while working in this mentorship are:
- Last year, Elizabeth raised an issue to add code for generating an IBM Validated software list. Some pre-work had already been done by Arsh, but a few things needed to be added, as the code was generating entries with null versions and null descriptions. Therefore, those entries need not be added to the list as they are not useful to any of our users. Except that, we want a separate script that allows you to specify which distributions from the list you want to build the JSON for. At last, we were only generating files for a small subset of the distributions used in the validated software list. Therefore, after solving all these issues and after thorough testing I got my first major PR merged with the main repository🎉.
- While working with the MySQL back-end, we noticed that the files of openSUSE present in the data repository were empty, therefore we needed to fix the creation of openSUSE data files. We learned that the way we were scraping data from the openSUSE was broken and we needed another way to scrape it. Besides that, there was some confusion about how to split the “name” into “package name” and “version” as they were both squished into “name”. Arsh and I thought of a strategy that we can work out with but still, we need some validation of what we’re thinking is true or not. Thanks to Christian Boltz from openSUSE who helped us with how to split the name and validate what we were thinking; surprisingly, we’re on the right path. Following that, the latest release of openSUSE 15.5 also needed to be added to our code. The code that we had needs to be refactored too, as for different openSUSE versions, we have the same lines of code that we can easily cut down by putting them in a loop. Therefore, I worked on these issues, halving the number of lines of code, and finally, it got merged successfully here.
- Our SDT tool was getting slower as search space was increasing day by day, therefore, Arsh in his last mentorship, proposed that we should shift from a No-SQL database to a MySQL database. That’s when he did the heavy lifting and took it to a proposed state. In the proposed state we used MariaDB as our MySQL database. Carrying it forward so that we can switch to it as it was one of the major milestones for this mentorship programme. Some edge cases were there when our application was failing on a file that was missing or broken, and creating an error. There was a need to add a check in our code if some file was added to Supported distros and isn’t available in our submodule, that was giving an error. Also, I added functionality to create a table in MariaDB for a particular source that we can pass as an argument as earlier we could only create all tables at once, even if we were required to edit or update just one table. Accordingly, we’ve updated our supported distros. Later we tested it for any edge cases we might be falling off. Once reviewed by Divya, Elizabeth, and Arsh, it got merged, and now we’re quite snappy and working well after the switch to the MySQL database. You should take a look at our tool here.
So what’s the next plan now? Was that the end? No, of course not, currently, we have a draft PR for UI changes, as we’re shifting from Angular to React. So you’ll be seeing major changes in the UI part of our Tool in the near future. As since we’re lazy, we want to automate a number of things in the future too, some of them are: Currently, our core repository doesn’t track the latest commit of the data repository, therefore they don’t sync and every time we’ve to make it work manually. One of the other major tasks is over time, as distro packages get updated, added, or deleted. Therefore, we need to recreate all the data files regularly after some time so that we’re not serving the wrong and stale packages to our users. There’s also a thought of having a separation of repositories, that is having a separate backend and frontend and they connect through API. So these are some issues or thoughts that we’ll be working on soon or these might be the goals for the next mentorship (a small teaser for future mentees).
Wait, How could I forget about my mentors? A special thanks to both of my mentors Elizabeth and Arsh, in these 3 months I’ve learned a lot, looking back I can say that I’ve gained a lot of things. They’ve been there every time I needed them despite the odd times when I pinged them, Sorry for that. Elizabeth is someone who’s there every time, you need some insights about some packages, links or anything, even if she doesn’t know about it, but she’ll bring it for you, she’s so flexible, understanding and very professional. The culture that she has developed here, I love that! While Arsh, is someone who helped me a lot, I preferred asking him rather than searching some issue on Google, and we usually have a meeting twice or thrice a week to discuss what we can do for a particular issue or the way our tool is going to be in future, what are things that need to be done. He’s awesome! And thanks once again. It was great working with you guys. I look forward to working again with you.
Now, at the end of my mentorship, I can associate myself a lot with the tool. I am a part of it, and I am proud of that. This wasn’t the end, I’ll keep looking and contributing to the tool because it’s “our” tool now. Future mentees, I know Arsh and Elizabeth won’t leave any doubts, but still, I’m always here if you want to reach out.
Thank you for your continued interest. I’m aware that you’ve been contemplating “our” tool. Haven’t had a chance to take a look yet? You can find it here: Software Discovery Tool On Github.
We enthusiastically encourage bug reports and feature requests from all contributors!

About Prince
I am a postgraduate student at the Indian Institute of Information Technology, Gwalior, majoring in Information Technology. I have a strong passion for problem-solving and enjoydeveloping innovative solutions. My journey in competitive programming has honed my problem-solving skills, primarily in C++, on various online platforms. I am proficient in several programming languages, including Python, C++, and JavaScript, and I’m constantly expanding my knowledge. My ultimate goal is to become a proficient problem solver. I have an insatiable appetite for challenges, so feel free to bring them on. In addition to my love for programming, I am also an avid sports enthusiast, both as a spectator and a player.
Learn more about the Open Mainframe Project Mentorship Program here.